AWS DynamoDB
On this page
- Highlights
- Suitable Use Cases
- Basics
- Official Guide:cheat sheet
- Global secondary index (GSI)
- Handle time series Data
- The difference between scan and query in dynamodb? When use scan / query?
- Scan vs Query
- Could I limit the return query/scan items size from dynamodb?
- Query with Sorting
- Query (and Scan) DynamoDB Pagination
- Hierarchical Data
- Principals of Data Modeling
- Tools
- References
- Highlights
- Suitable Use Cases
- Basics
- Official Guide:cheat sheet
- Global secondary index (GSI)
- Handle time series Data
- The difference between scan and query in dynamodb? When use scan / query?
- Scan vs Query
- Could I limit the return query/scan items size from dynamodb?
- Query with Sorting
- Query (and Scan) DynamoDB Pagination
- Hierarchical Data
- Principals of Data Modeling
- Tools
- References
DynamoDB is designed to hold a large amount of data. That is why data is partitioned. When you request the data, you do not want to spend time and compute power to gather data from various tables. That is why DynamoDB does not have joins. The solution is to store data in a form that is already prepared for our access patterns.
🚀A Deep Dive into Amazon DynamoDB Architecture
Highlights
- Adapting to the traffic patterns of user applications improves the overall customer experience
- To improve stability, it’s better to design systems for predictability over absolute efficiency
- For high durability, perform continuous verification of the data-at-rest
- Maintaining high availability is a careful balance between operational discipline and new features
- Keep the number of tables you use to a minimum. For most applications,
a single tableis all you need - However, for
time series data, you can often best handle it by usingone table per application per period. Global secondary index (GSI)is the central part of most design patterns in a DynamoDB single table design.- Principals of #DynamoDB data modeling:
draw ER,GET ALL ACCESS PATTERNS,denormalize,avoid scans,filters,transactions,prefers eventually consistent reads, learn #singletabledesign - The most simple denormalization is to
contain all the data in one item.
Suitable Use Cases
DynamoDB is a particularly good fit for the following use cases:
Applications with large amounts of data and strict latency requirements. As your amount of data scales, JOINs and advanced SQL operations can slow down your queries. With DynamoDB, your queries have predictable latency up to any size, including over 100 TBs!
Serverless applications using AWS Lambda. AWS Lambda provides auto-scaling, stateless, ephemeral compute in response to event triggers. DynamoDB is accessible via an HTTP API and performs authentication & authorization via IAM roles, making it a perfect fit for building Serverless applications.
Data sets with simple, known access patterns. If you're generating recommendations and serving them to users, DynamoDB's simple key-value access patterns make it a fast, reliable choice.
Basics
Partition (hash) key (PK): Defines in which portion the data is stored. Use as a distinct value as possible. You can only query by the exact value. UUID is commonly used. Ensure even distribution of data across partitionsSort (range) key (SK): Defines the sorting of items in the partition. It is optional. Combined with the partition key, it defines the primary key of the item. You can query it by condition expression (=, >, <, between, begins_with, contains, in) combined with PK. You can never leave out PK when querying.Local secondary index: Allows defining another sort key for the same partition key. It can only be created when you create the table. Compared to the global secondary index, it offers consistent reads. You can have up to five LSI on a table.Global secondary index (GSI): Allows defining a new partition and optional sort key. It should be preferred compared to the LSI, except when you need consistent reads. You can have up to20 GSIon a table, so you would try to reuse them within the same table. GSI is the central part of most design patterns in a single table design. Both LSI and GSI are implemented as copying all the data to a new table-like structure. You have projections that enable you to copy only the data that you need.Attributescan bescalar (single value)orcomplex (list, maps, sets of unique values).Page size limit for query and scan: There is a limit of1 MBper page, per query or scan.KeyType:HASHforPartition keyandRANGEforSort key
Official Guide:cheat sheet
Global secondary index (GSI)
Query data using attributes other than the primary key. This allows you to effectively use different "partition keys" for different access patterns without scanning the entire table.
- Up to 20 GSIs per table.
- Project all attributes, only the key attributes, or a subset of attributes.
- Improve query performance by avoiding full table scans.
- Support for different access patterns within a single table.
- Projection Type
- Storage costs:
- KEYS_ONLY: Lowest storage cost, as it only stores the primary key and index key attributes.
- INCLUDE: Moderate storage cost, storing only specified attributes in addition to keys.
- ALL: Highest storage cost, as it duplicates all attributes from the base table.
- Query performance:
- KEYS_ONLY: Fastest for queries that only need key attributes.
- INCLUDE: Efficient for queries requiring specific attributes.
- ALL: Best for queries needing all attributes, avoiding additional base table lookups.
- Flexibility:
- KEYS_ONLY: Least flexible, limited to key attributes only.
- INCLUDE: Balanced flexibility, allowing selection of specific attributes.
- ALL: Most flexible, supporting all possible queries without table lookups.
- Consistency:
- KEYS_ONLY and INCLUDE: May require additional base table lookups for non-projected attributes.
- ALL: Provides eventual consistency for all attributes without additional lookups.
- Write performance:
- KEYS_ONLY: Fastest write performance due to minimal data duplication.
- INCLUDE: Moderate write performance, updating only specified attributes.
- ALL: Slowest write performance, as all attributes must be updated in the index.
- Storage costs:
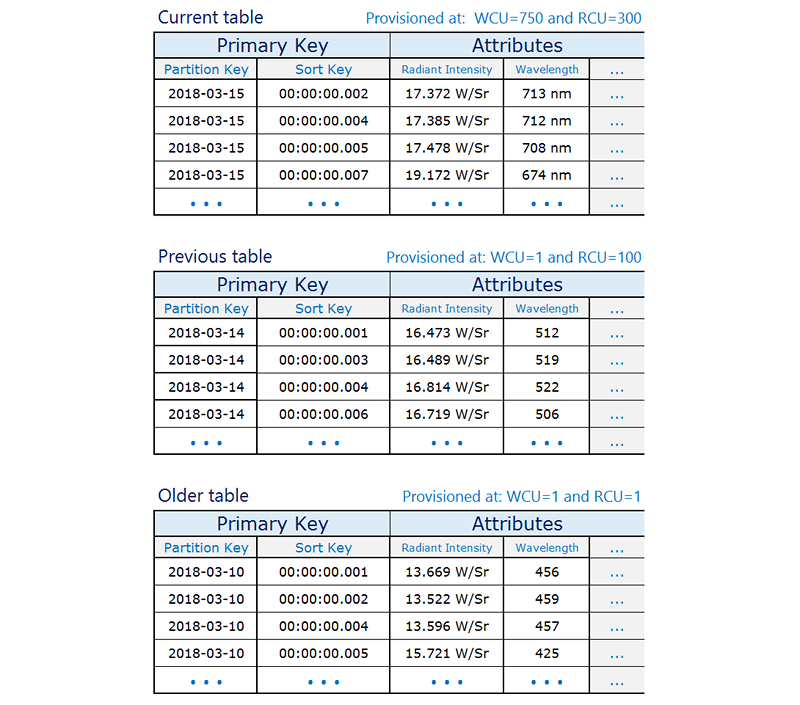
Handle time series Data
Scenario #1
Read today's events most frequently, yesterday's events much less frequently, and then older events very little at all
The idea is to allocate the required resources for the current period that will experience the highest volume of traffic and scale down provisioning for older tables that are not used actively, therefore saving costs.
The following design pattern often handles this kind of scenario effectively:
Create one table per period, provisioned with the required read and write capacity and the required indexes.Before the end of each period, prebuild the table for the next period. Just as the current period ends, direct event traffic to the new table. You can assign names to these tables that specify the periods they have recorded.As soon as a table is no longer being written to, reduce its provisioned write capacity to a lower value(for example, 1 WCU), and provision whatever read capacity is appropriate. Reduce the provisioned read capacity of earlier tables as they age. You might choose to archive or delete the tables whose contents are rarely or never needed.
The difference between scan and query in dynamodb? When use scan / query?
A scan operation always scan the entire table before it filters out the desired values, which means it takes more time and space to process data operations such as read, write and delete.
Scan vs Query
- scan: fetches all elements and only after does filtering. It is not efficient.
- query: only works
against index fields. You can't run a query against a non index field. If you could run query against any field then there would be no reason for scan to exist. If you want to run a query instead of an inefficient scan,you have to use a field you have defined in either the primary key, or a secondary index.
Could I limit the return query/scan items size from dynamodb?
No. Unfortunately there is no Query options or any other operation that can guarantee x items in a single request.
To understand why this is the case (it's not just laziness on Amazon's side), consider the following extreme case: you have a huge database with one billion items, but do a very specific query which has just 5 matching items, and now making the request you wished for: "give me back 5 items". Such a request would need to read the entire database of a billion items, before it can return anything, and the client will surely give up by then. So this is not how DyanmoDB's Limit works. It limits the amount of work that DyanamoDB needs to do before responding. So if Limit = 100, DynamoDB will read internally 100 items, which takes a bounded amount of time. But you are right that you have no idea whether it will respond with 100 items (if all of them matched the filter) or 0 items (if none of them matched the filter).
So to do what you want to do efficiently, you'll need to think of a different way to model your data - i.e., how to organize the partition and sort keys. There are different ways to do it, each has its own benefits and downsides, you'll need to consider your options for yourself.
Query with Sorting
DynamoDB offers only one way of sorting the results on the database side - using the sort key. If your table does not have one, your sorting capabilities are limited to sorting items in application code after fetching the results. However, if you need to sort DynamoDB results on sort key descending or ascending, you can use following syntax:
const AWS = require('aws-sdk');AWS.config.update({region:'us-east-1'});const dynamoDB = new AWS.DynamoDB.DocumentClient();dynamoDB.query({TableName: 'my-table',IndexName: 'Index', // Main oneKeyConditionExpression: 'id = :hashKey and date > :rangeKey'ExpressionAttributeValues: {':hashKey': '123',':rangeKey': 20150101},ScanIndexForward: true // true or false to sort by "date" Sort/Range key ascending or descending}).promise().then(data => console.log(data.Items)).catch(console.error);
Query (and Scan) DynamoDB Pagination
Both Query and Scan operations returns results up to 1MB of items. If you need to fetch more records, you need to invoke a second call to fetch the next page of results. If LastEvaluatedKey is present in response object, this table has more items like requested and another call with ExclusiveStartKey should be sent to fetch more of them:
const getAll = async () => {let result, accumulated, ExclusiveStartKey;do {result = await DynamoDB.query({TableName: argv.table,ExclusiveStartKey,Limit: 100,KeyConditionExpression: 'id = :hashKey and date > :rangeKey'ExpressionAttributeValues: {':hashKey': '123',':rangeKey': 20150101},}).promise();ExclusiveStartKey = result.LastEvaluatedKey;accumulated = [...accumulated, ...result.Items];} while (result.Items.length || result.LastEvaluatedKey);return accumulated;};getAll().then(console.log).catch(console.error);
Hierarchical Data
A good primary key does at least two things:
It enables you to uniquely identify each item for writes & updates, and
It evenly distributes your data across the partition key Ideally your primary key will also satisfy at least one of your read access patterns as well.
use the Store Number as a simple primary key
A global secondary index
- a HASH key of Country, indicating the country where the store is located, and
- a RANGE key named StateCityPostcode that is a string combining the State, City, and Postcode with each element separated by the pound sign (
<STATE>#<CITY>#<POSTCODE>). For example, a store in Omaha, NE would be stored asNE#OMAHA#68144.
Principals of Data Modeling
- Draw the ER diagram as you usually do.
Get all access patterns before starting data modeling.- Denormalization
- Avoid hot partition.
- Do not use scan on large datasets.
- Do not use a filter on large datasets.
- Prefers eventually consistent reads.
- The data model is hard to change.
- Prepare for data model change.
- Avoid transactions.
| RDBMS data modeling | DynamoDB |
|---|---|
| Access patterns can be defined later | Access patterns must be defined before data modeling |
| Normalization | Denormalization |
| Powerful ad hoc queries (SQL) | Limiting query capabilities |
| Powerful transactions | Limiting transactions |
| Reasonably flexible to change the data model | Hard to change the data model |
- If you need to put ID in a sort key, consider using KSUID (K-Sortable Unique Identifier) instead of the commonly used UUID.
Tools
DynamoDB Toolbox
The DynamoDB Toolbox is a set of tools that makes it easy to work with Amazon DynamoDB and the DocumentClient. It's designed with Single Tables in mind, but works just as well with multiple tables. It lets you define your Entities (with typings and aliases) and map them to your DynamoDB tables. You can then generate the API parameters to put, get, delete, update, query, scan, batchGet, and batchWrite data by passing in JavaScript objects. The DynamoDB Toolbox will map aliases, validate and coerce types, and even write complex UpdateExpressions for you
dynamodb-paginator
Implementation of pagination for DynamoDB from the following article
import { getPaginatedResult, decodeCursor } from "dynamodb-paginator";const limit = 25;const params = decodeCursor(cursor) || {TableName: "Users",Limit: limit,KeyConditionExpression: "id = :id",ExpressionAttributeValues: {":id": "1",},};const result = await dynoDB.query(params).promise();return getPaginatedResult < IUser > (params, limit, result);
Sort-Key
Generating DynamoDB sort keys from multiple string parts as recommended by AWS. It uses # as separator and knows how to escape it when given on one of the key parts.
[country]#[region]#[state]#[county]#[city]#[neighborhood]import SortKey from 'sort-key';const SK = SortKey.generate('1532208', '2020-09-11T15:30:06.822Z');// 1532208#2020-09-11T15:30:06.822Zconst [order, time] = SortKey.parse(SK);// "1532208" "2020-09-11T15:30:06.822Z"
dynamodb-update-expression
A small library providing the solution to generate DynamoDB update expression by comparing the original data with update/remove JSON object.
var dynamodbUpdateExpression = require("dynamodb-update-expression");var updateExpression = dynamodbUpdateExpression.getUpdateExpression(original,update);var removeExpression = dynamodbUpdateExpression.getRemoveExpression(original,remove);
Sample output
{"UpdateExpression": "SET #lastName = :lastName, #phones = :phones, #family = :family, #profilebusinesswebsite = :profilebusinesswebsite, #profilebusinessphone = :profilebusinessphone, #profileoffice = :profileoffice REMOVE #profilecompany","ExpressionAttributeNames": {"#lastName": "lastName","#phones": "phones","#family": "family","#profilebusinesswebsite": "profile.business.website","#profilebusinessphone": "profile.business.phone","#profileoffice": "profile.office","#profilecompany": "profile.company"},"ExpressionAttributeValues": {":lastName": "L. Doe",":phones": ["1111-2222-333", "5555-4444-555", "2222-4444-555"],":family": [{"id": 2,"role": "mother"}],":profilebusinesswebsite": "www.acmeinc.com",":profilebusinessphone": "111222333",":profileoffice": "1234 Market Street"}}
Spark+DynamoDB
Plug-and-play implementation of an Apache Spark custom data source for AWS DynamoDB.
Serverless Console

Serverless Console is an alternative UI for AWS Cloudwatch. Its focus is on "serverless functions" but it can also be used for any kind of log group.
References
- What I’ve Learned From Using AWS DynamoDB in Production for More Than 3 Years
- How to Make a Serverless GraphQL API using Lambda and DynamoDB
- How to use DynamoDB global secondary indexes to improve query performance and reduce costs

Global secondary indexes enhance the querying capability of DynamoDB. This post shows how you can use global secondary indexes and patterns such as data filtering and data ordering to achieve read isolation and reduce query costs. The recent limit increase of the maximum number of global secondary indexes per DynamoDB table from 5 to 20 can help you apply these usage patterns without worrying about hitting limits.